
Le Machine Learning, aussi appelé apprentissage automatique en français, est une forme d'intelligence artificielle permettant aux ordinateurs d'apprendre sans avoir été programmés explicitement à cet effet. Cette technologie permet de développer des programmes informatiques pouvant changer en cas d'exposition à de nouvelles données. Découvrez la définition, le fonctionnement et les secteurs d'applications du Machine Learning.
Le Machine Learning est une méthode d'analyse de données permettant d'automatiser le développement de modèle analytique. Par le biais d'algorithmes capables d'apprendre de manière itérative, le Machine Learning permet aux ordinateurs de découvrir des insights cachées sans être programmés pour savoir où les chercher.
Aux origines, le Machine Learning est né grâce aux technologies de reconnaissance de pattern et à la théorie selon laquelle les ordinateurs peuvent apprendre sans être programmés pour effectuer des tâches spécifiques. Les chercheurs intéressés par l'intelligence artificielle souhaitaient vérifier si les ordinateurs pouvaient apprendre à partir de données. L'aspect itératif du Machine Learning est essentiel, car il permet aux modèles de s'adapter indépendamment lorsqu'ils sont exposés à de nouvelles données. Ils apprennent des précédents calculs pour créer des décisions et des résultats fiables et répétables.
Les algorithmes de Machine Learning ne sont pas une nouveauté, mais ce n'est que depuis peu qu'il est possible d'appliquer des calculs mathématiques complexes de plus en plus vite au Big Data. Le Machine Learning est aujourd'hui utilisé dans de nombreux domaines, comme le développement de véhicules autonomes, les systèmes de recommandations en ligne comme ceux de Netflix et Amazon, l'analyse de sentiments de clients, ou encore la détection de fraude.
Le regain d'intérêt pour le Machine Learning est lié aux mêmes facteurs que ceux qui ont suscité l'attention au tour du data mining et des technologies analytiques. Les données sont de plus en plus nombreuses et diversifiées, la puissance informatique est moins chère que jamais, et le stockage de données est désormais abordable.
Par conséquent, il est désormais possible de produire rapidement et automatiquement des modèles capables d'analyser plus rapidement des volumes de données plus importants et plus complexes. Ce faisant, les entreprises ont davantage de chances d'identifier des opportunités lucratives ou d'éviter les risques inconnus.
Machine Learning : qui l'utilise ? Quels sont les secteurs d'application de cette technologie ?

Le Machine Learning est utilisé dans de nombreuses industries, et même dans les domaines créatifs comme la peinture ou le cinéma. Les entreprises ont compris l'avantage compétitif procuré par la capacité de collecter des informations en temps réel à partir de données.
Services financiers
Les banques et autres entreprises de l'industrie de la finance utilisent le Machine Learning pour découvrir des informations importantes au sein des données, et pour empêcher la fraude. Les insights permettent d'identifier les opportunités d'investissement, tandis que le Data Mining permet d'identifier les clients à haut risque. La cybersurveillance permet quant à elle de repérer les signes de fraude.
Gouvernement
Les agences gouvernementales peuvent utiliser le Machine Learning pour traiter les données en provenance de nombreuses sources qu'elles ont à disposition. En analysant les données de capteurs, par exemple, elles peuvent identifier les possibilités d'augmenter leur efficience et d'économiser de l'argent. Le Machine Learning permet également de détecter les fraudes et de réduire le nombre de vols d'identités.
Santé
L'on fait de plus en plus appel au Machine Learning dans le secteur de la santé, notamment grâce à l'essor des objets connectés et autres capteurs permettant d'utiliser les données pour accéder aux données de santé d'un patient en temps réel. Cette technologie peut aussi aider les experts médicaux à analyser les données pour identifier des tendances alarmantes afin d'améliorer les diagnostics et les traitements.
Marketing
Les sites web qui recommandent des produits basés sur les précédents achats de l'utilisateur utilisent le Machine Learning pour analyser l'historique d'achat des clients et proposer des produits qui pourraient les intéresser. La capacité de collecter les données, de les analyser et de les utiliser pour personnaliser l'expérience de shopping représente le futur de la vente au détail.
Gaz et pétrole
Le Machine Learning permet également de trouver de nouvelles sources d'énergie, d'analyser les minéraux dans le sol, ou encore de prédire les pannes de capteurs dans les raffineries. Cette technologie permet de rendre la distribution de pétrole plus efficiente et plus économique.
Transports
Dans l'industrie des transports, les données sont analysées pour identifier des patterns et des tendances. Ainsi, les itinéraires sont plus efficients et les problèmes potentiels peuvent être prédits pour augmenter la rentabilité. L'analyse de données et les modèles du Machine Learning sont utilisés comme de précieux outils par les entreprises de livraison, les transports publics et les autres entreprises de transport.
Quelles sont les principales méthodes de Machine Learning ?

Les deux méthodes de Machine Learning les plus couramment utilisées sont l'apprentissage supervisé et l'apprentissage non supervisé.
Apprentissage supervisé
Les algorithmes d'apprentissage supervisé sont formés à l'aide d'exemples étiquetés. Par exemple, un appareil peut avoir des points de données étiquetés F (failed) ou R (runs). L'algorithme reçoit un ensemble d'entrées ainsi que les sorties correctes correspondantes. Pour détecter les erreurs, il apprend en comparant les sorties aux résultats corrects attendus. Il modifie ensuite son modèle en conséquence.
Les méthodes telles que la classification, la régression et la prédiction permettent à l'apprentissage supervisé d'utiliser des patterns pour prédire la valeur d'une étiquette ou de données supplémentaires non étiquetées. Cette méthode d'apprentissage est couramment utilisée dans les applications où les données historiques sont utilisées pour prédire des événements futurs. Par exemple, elle peut être utilisée pour anticiper les transactions frauduleuses ou le risque qu'un client d'assurance ait un accident.
Apprentissage non supervisé
L'apprentissage non supervisé est utilisé pour les données qui n'ont pas d'étiquettes historiques. Le système ne connaît pas la bonne réponse, et l'algorithme doit trouver par lui-même les éléments présentés. L'objectif consiste à explorer les données et à y trouver une structure. Cette méthode fonctionne bien pour les données de transaction.
Elle permet, par exemple, d'identifier des segments de consommateurs présentant des attributs similaires. Ces segments peuvent être traités de manière similaire dans le cadre d'une campagne de marketing. Elle offre également la possibilité de trouver les attributs clés qui séparent les différents segments de consommateurs. Ces algorithmes servent à segmenter du texte, à recommander des produits et à identifier des sources de données.
Machine Learning : quels sont les avantages et les inconvénients ?

Le Machine Learning permet de prédire le comportement des clients ou de créer le système d'exploitation des voitures à conduite autonome. En ce qui concerne les avantages, il peut aider les entreprises à comprendre leurs clients à un niveau plus profond.
En collectant les données des clients et en les corrélant avec les comportements au fil du temps, les algorithmes de Machine Learning parviennent à apprendre des associations et à aider les équipes à adapter le développement des produits. Ainsi, les initiatives marketing sont adaptées à la demande des clients. Certaines entreprises utilisent le Machine Learning comme moteur principal de leur modèle économique.
Toutefois, le Machine Learning présente également des inconvénients. Tout d'abord, il peut être coûteux. Les projets d'apprentissage automatique sont généralement menés par des spécialistes des données, qui perçoivent des salaires élevés. Ces projets nécessitent également une infrastructure logicielle qui peut être coûteuse.
En outre, les algorithmes formés sur des ensembles de données qui excluent certaines populations ou contiennent des erreurs peuvent conduire à des modèles inexacts du monde qui échouent. Lorsqu'une entreprise fonde des processus commerciaux essentiels sur des modèles biaisés, elle peut se heurter à des problèmes de réglementation et de réputation.
Comment apprendre le machine learning ?

Il n'est pas surprenant que la toute première question que se posent la plupart des étudiants machine learning concerne la conception de leur cours d'apprentissage. À un niveau élevé, cela signifie généralement les sujets et les matières du plan d'étude. Un programme d'études soigneusement planifié est essentiel.
En plus d'une liste intuitive de sujets, il existe un autre concept que chaque étudiant en machine learning doit comprendre au tout début de son parcours. Il faut apprendre en utilisant l'approche descendante et non ascendante.
Approche descendante pour apprendre le Machine Learning
L'approche descendante (Top-down) consiste à passer d'une solution de haut niveau à la rigueur d'une méthode appliquée. Cette stratégie ne nécessite pas d'investir un temps considérable dans l'étude de la théorie avant de passer aux aspects pratiques. Il s'agit plutôt de se procurer les bons outils et de travailler à l'exécution des tâches avant d'apprendre comment tout fonctionne. L'objectif final est de résoudre une tâche du monde réel en utilisant les outils et méthodes de haut niveau à votre disposition.
Cours en ligne ouverts et massifs (MOOC)
Le MOOC ou (massive open online course) est un excellent exemple de méthode descendante en action. Il offre une approche pratique de l'apprentissage. Grâce à des scénarios de cas réels, à la visualisation et à une tonne d'exercices, les apprenants peuvent profiter du processus d'apprentissage sans être submergés par des concepts mathématiques complexes.
Bootcamps
Les bootcamps sont un autre moyen d'apprendre le machine learning. Sa principale différence avec un diplôme concerne le temps qu'il faut pour les compléter. L'ensemble du processus de bootcamp ne prend généralement pas plus de 6 mois, avec une moyenne de 3 à 4 mois. Certains garantissent même que leurs étudiants recevront une offre d'emploi à la fin.
Approche ascendante du machine learning
L'approche ascendante constitue une approche traditionnelle de l'apprentissage. Il faut d'abord apprendre la partie théorique, et ensuite seulement passer lentement à la partie pratique. En termes d'apprentissage automatique, cela signifie :
- Acquérir un solide bagage mathématique et des compétences en programmation
- apprendre les principes fondamentaux du backend/développement logiciel
- comprendre les bases de données, l'interrogation et le traitement des données
- maîtriser les principes d'extraction, de nettoyage, de manipulation et d'exploration des données.
Ce n'est qu'ensuite qu'il faudra passer aux principes de base des algorithmes de traitement automatique des données, ce qui prendra au moins trois ans. Ces bases aident à comprendre les futures avancées du ML.
Master en ligne
Il est important de dire que le passage à des cours en ligne n'affecte pas la qualité du programme. Au contraire, les étudiants en ligne font état de taux de satisfaction plus élevés en ce qui concerne la communication avec leurs camarades de classe et le personnel universitaire. Les étudiants à temps plein qui sont passés au format en ligne n'ont constaté aucun changement en termes de programme éducatif.
Concepts du Machine Learning et sujets d'apprentissage
À présent, il faut bien comprendre COMMENT apprendre le Machine Learning. Sur quoi exactement il faut se concentrer. À savoir que les étudiants qui suivent l'approche descendante ne se concentrent pas sur le même sujet que ceux qui abordent le ML de manière ascendante.
Quelles sont les différences entre data mining, machine learning et deep learning ?
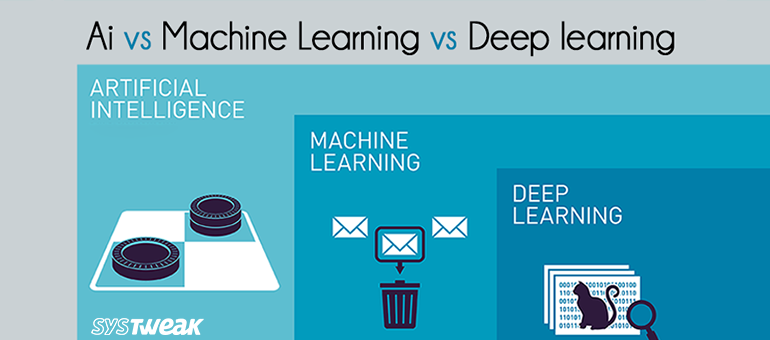
Le data mining, le machine learning et le deep learning ont le même objectif, à savoir l'extraction d'insights, de patterns et de relations pouvant être utilisées pour prendre des décisions. Toutefois, leurs approches et leurs bénéfices sont différents. Le Data Mining peut être considéré comme un ensemble de différentes méthodes d'extraction d'informations depuis les données. Il implique des méthodes statistiques traditionnelles et du Machine Learning. Le Data Mining repose sur différentes méthodes en provenance de différents domaines pour identifier des patterns auparavant inconnues depuis les données. Parmi ces méthodes, on compte les algorithmes statistiques, le Machine Learning, les analyses de texte, les analyses de séries temporelles, et d'autres domaines d'analyse. Le Data Mining inclut également l'étude et l'utilisation du stockage de données et la manipulation de données.
La principale différence est que le machine learning, comme les modèles statistiques, ont pour but de comprendre la structure des données. Les modèles statistiques reposent sur une théorie prouvée mathématiquement derrière le modèle, mais les données doivent aussi correspondre à certaines caractéristiques. Le Machine Learning s'est développé à partir de la capacité à utiliser les ordinateurs pour structurer les données, même si on ignore à quoi cette structure s'apparente. Le test pour un modèle de machine Learning est la validation d'une erreur sur de nouvelles données, et non un test théorique qui prouve une hypothèse. Le Machine Learning repose généralement sur une approche itérative pour apprendre des données, et l'apprentissage peut donc être facilement automatisé. Les tests sont effectués jusqu'à ce qu'une pattern robuste soit trouvée.
De son côté, le Deep Learning combine les avancées dans le domaine de la puissance informatique et les réseaux de neurones artificiels spécifiques pour apprendre des patterns complexes au sein de larges quantités de données. Les techniques de Deep Learning sont actuellement utilisées pour l'identification d'objets dans les images, et de mots dans les sons. Les chercheurs visent à présent à appliquer la reconnaissance de patterns à des tâches plus complexes comme la traduction automatique de langage, les diagnostics médicaux et d'autres problèmes sociaux ou commerciaux importants.
Histoire du machine learning
La découverte et le perfectionnement des méthodes statistiques ont marqué l'année 1950. Cette même année, des recherches pionnières sur le machine learning ont été menées à l'aide d'algorithmes simples.
En ce qui concerne les méthodes bayésiennes, elles ont été introduites en 1960 pour l'inférence probabiliste dans l'apprentissage automatique. De fait, en 1970, le winter de l'IA a été déclenché en raison du pessimisme relatif à l'efficacité du machine learning.
En 1980, la redécouverte de la rétropropagation a entraîné une résurgence de la recherche sur les machines learning. De fait, les travaux sur ce sujet sont passés en 1990 d'une approche fondée sur les connaissances à une approche fondée sur les données. Les scientifiques ont commencé à créer des programmes pour que les ordinateurs puissent analyser de grandes quantités de données. Ceux-ci tirent des conclusions – ou « apprennent » – à partir des résultats.
Les machines à vecteurs de support (SVM) et les réseaux neuronaux récurrents (RNN) deviennent alors populaires. Par ailleurs, les domaines de la complexité informatique par le biais des réseaux neuronaux et du calcul super-Turing font leur apparition.
Les clusters de vecteurs de support et autres méthodes à noyau et méthodes de machine learning non supervisées se répandent dans les années 2000. Le deep learning devient réalisable en 2010, permettant au machine learning de devenir une partie intégrante de nombreuses applications et services logiciels largement utilisés.
Les meilleurs langages de programmation pour le machine learning

Langage de programmation Python
Plus de 8,2 millions de développeurs dans le monde utilisent Python pour coder. Il occupe la première place dans le dernier classement annuel des langages de programmation populaires établi par IEEE Spectrum, avec un score de 100.
Les bibliothèques et paquets intégrés à Python fournissent une base de code. De fait, les ingénieurs en machine learning n'ont pas besoin de partir de zéro pour écrire. En outre, la nature multi-paradigme et flexible de Python permet à ces derniers d'aborder un problème de la manière la plus simple possible.
Langage de programmation R
Le langage R peut également être utilisé par des non-programmeurs. Notamment les mineurs de données, les analystes de données et les statisticiens. Une partie essentielle du rôle quotidien d'un ingénieur en machine learning est de comprendre les principes statistiques. De fait, ils sont capables d'appliquer ces principes aux mégadonnées. Le langage de programmation R constitue un choix idéal lorsqu'il s'agit de calculer de grands nombres.
Langage de programmation Java
Java gagne en popularité auprès des ingénieurs en machine learning ayant une formation en développement Java. En fait, ils n'ont pas besoin d'apprendre un nouveau langage de programmation comme Python ou R pour mettre en œuvre l'apprentissage automatique. De nombreuses organisations disposent déjà d'énormes bases de code Java. La plupart des outils open source de traitement des données volumineuses, comme Hadoop et Spark, sont écrits en Java. Son utilisation permet de s'intégrer plus facilement aux dépôts de code existants.
Langage de programmation Julia
Julia est un langage de programmation dynamique polyvalent et performant. Il s'impose comme un concurrent potentiel de Python et R avec de nombreuses fonctionnalités prédominantes exclusivement destinées à l'apprentissage automatique.
Julia a été développée spécifiquement pour implémenter les requêtes mathématiques et scientifiques de base. En fait, ces derniers sous-tendent la plupart des algorithmes d'apprentissage automatique.
Le code Julia est compilé en Just-in-Time ou à l'exécution en utilisant le framework LLVM. Cela permet aux ingénieurs de machine learning de bénéficier d'une vitesse élevée sans avoir à recourir à des techniques de profilage.
Les plus grands fournisseurs de solutions en machine learning

Plateforme IBM Watson
Parmi les principales plateformes d'IA, Watson est sans doute la plus avancée en termes d'offres commerciales. En fait, il s'agit d'une solution « ouverte et multi-cloud qui permet d'automatiser le cycle de vie de l'IA ».
Plus que d'autres fournisseurs, IBM s'attache à fournir une suite d'outils d'IA que les entreprises peuvent choisir quand et où elles les appliquent. Le machine learning fait partie de ces modules. Chez IBM, ce service se concentre sur les informations prédictives pour les entreprises.
DeepMind de Google
DeepMind bénéficie d'une bonne réputation pour avoir construit une IA capable d'égaler un humain dans le jeu de société Go. Cette plateforme fait partie des leaders dans le domaine de l'IA bien que Google ne détienne pas de parts de marché dans le cloud computing. Actuellement, la plateforme se concentre principalement sur l'utilisation du machine learning pour la recherche et dans ses propres outils.
La plateforme d'IA Azure de Microsoft
La plateforme Azure AI de Microsoft utilise le machine learning principalement pour analyser des images et faire des prédictions à partir de données.
Azure a été conçu pour offrir des fonctionnalités d'informatique de pointe afin de faciliter l'obtention d'informations et la prise de décisions fondées sur les données. Elle se concentre sur les déploiements les plus simples, qui permettent aux développeurs d'expérimenter quels algorithmes utiliser afin d'obtenir des résultats rapidement.
Plateforme d'IA d'Amazon
Dans l'ensemble, Amazon est l'entreprise qui se concentre le plus sur la mise en place et le fonctionnement rapide du ML dans les organisations. Son objectif consiste à mettre l'IA et le machine learning entre les mains des développeurs, rapidement et efficacement. En fait, l'accent a été mis sur le service aux scientifiques des données avec des outils conçus spécifiquement pour aider à analyser les données efficacement.
- Partager l'article :
